How fast is the FieldTrip buffer for realtime data streaming?
For real-time use of the buffer it is relevant to know how fast it can handle read and write requests. For a write request, the time depends on the number of channels and on the number of samples in the data block.
The following benchmarks have been run using the rt_benchmark script in the realtime directory on the following computer
- fcdc334: Dell PC with Windows XP, P4 2.8 GHz, 1GB RAM
- mentat204, mentat205, mentat232: 64-bit Linux, Core 2 Quad 2.8 GHz, 8GB RAM
- laptop: 32-bit Linux, 1.6Ghz Pentium M, 512 MB RAM
The first name in the legend always refers to the machine where the rt_benchmark script was run from, whereas the other name behind the dash refers to the machine that contained the buffer, with the exception of dma, which means that the buffer was kept in the same MATLAB instance, thus involving no TCP/IP communication.
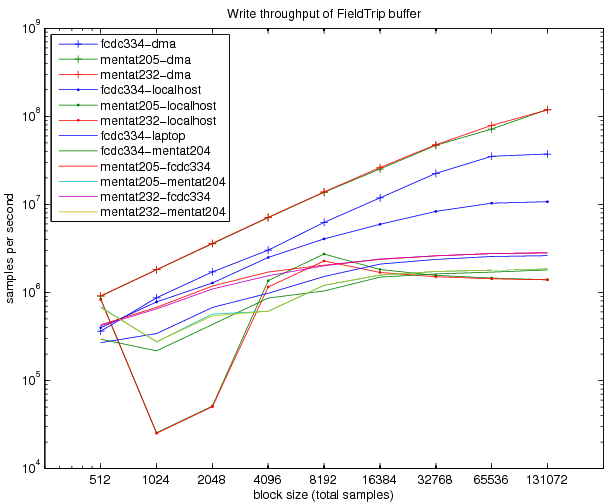
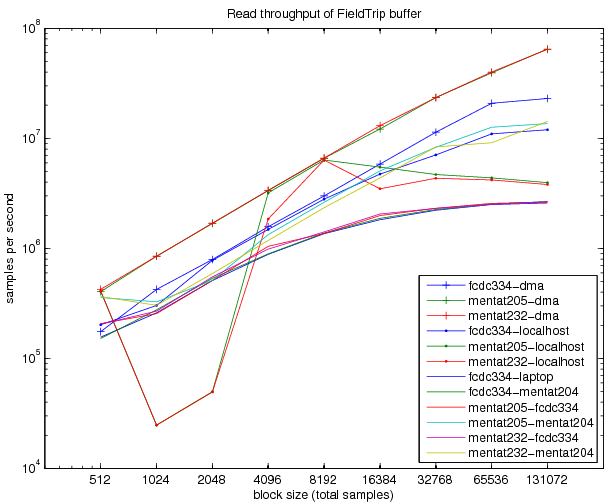
The dramatic dip for the mentat2xx-localhost connections needs further investigation.
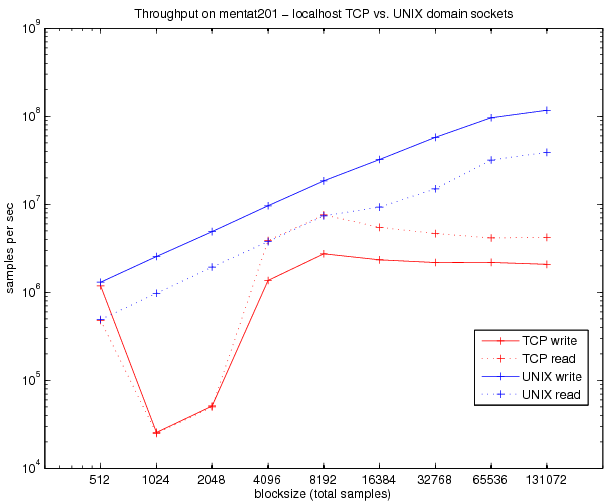
Update 19-08-2010: After implementing an alternative communication channel using local UNIX domain sockets, here is an updated figure for a single 64-bit Linux machine. Communication over local domain sockets is generally faster, but most importantly, it is more consistent across blocksizes and scales linearly like the DMA throughput.
Older comparisons involving Apple computers
The benchmarking results presented in the table below were determined with the demo_buffer and the test_benchmark command-line executables, both present in the directory fieldtrip/realtime/buffer/test. Both applications were running on the same computer, i.e. using the local TCP stack. The blocksize below is the number of channels times the number of samples per block in each write request. The result is expressed in samples per second, and was measured over multiple seconds. Each sample is 4 bytes.
The tests have been performed on and between the following computer
- powerbook: Apple PowerBook G4 PPC 1.33GHz, 1.25GB RAM, macOS 10.4.11
- manzana: Apple Mac Pro 2x 2.66GHz Dual-Core Intel Xeon, 2GB RAM, macOS 10.5.8
- fcdc273: Dell PC with Windows XP, P4 2.8GHz, 2GB RAM
Writing to localhost on powerbook
| chans*samples=blocksize | samples/sec | details |
|---|---|---|
| 32*16=512 | 70400 | localhost, tcp, stateless |
| 32*64=2048 | 265625 | localhost, tcp, stateless |
| 32*256=8192 | 883097 | localhost, tcp, stateless |
| 64*256=16384 | 1330380 | localhost, tcp, stateless |
| 128*256=32768 | 1441792 | localhost, tcp, stateless |
| 256*256=65536 | 1907097 | localhost, tcp, stateless |
| chans*samples=blocksize | samples/sec | details |
| 256*256=65536 | 1736704 | localhost, tcp, statefull |
| chans*samples=blocksize | samples/sec | details |
| 32*256=8192 | 7747584 | dma |
| 64*256=16384 | 8894464 | dma |
| 128*256=32768 | 7766016 | dma |
| 256*256=65536 | 7818444 | dma |
The best result above for statefull tcp corresponds with 60 kHz @ 32 channels or 15 kHz @ 128 channels.
Writing to localhost on manzana
| chans*samples=blocksize | samples/sec | details |
|---|---|---|
| 32*16=512 | 127522 | localhost, tcp, stateless |
| 32*32=1024 | 247466 | localhost, tcp, stateless |
| 32*64=2048 | 498048 | localhost, tcp, stateless |
| 32*128=4096 | 1027373 | localhost, tcp, stateless |
| 32*256=8192 | 2039808 | localhost, tcp, stateless |
| 64*256=16384 | 3952267 | localhost, tcp, stateless |
| 128*256=32768 | 167936 (?) | localhost, tcp, stateless |
| 256*256=65536 | 327680 (?) | localhost, tcp, stateless |
Writing to localhost on fcdc273
| chans*samples=blocksize | samples/sec | details |
|---|---|---|
| 32*16=512 | 10490 | localhost, tcp, stateless |
| 32*32=1024 | 20813 | localhost, tcp, stateless |
| 32*64=2048 | 41660 | localhost, tcp, stateless |
| 32*128=4096 | 76082 | localhost, tcp, stateless |
| 32*256=8192 | 125106 | localhost, tcp, stateless |
| 64*256=16384 | 172153 | localhost, tcp, stateless |
| 128*256=32768 | 223288 | localhost, tcp, stateless |
| 256*256=65636 | crash! | localhost, tcp, stateless |
Writing from fcdc273 to manzana
| chans*samples=blocksize | samples/sec | details |
|---|---|---|
| 32*16=512 | 10925 | remote host (100Mbps), tcp, stateless |
| 32*32=1024 | 21943 | remote host (100Mbps), tcp, stateless |
| 32*64=2048 | 43370 | remote host (100Mbps), tcp, stateless |
| 32*128=4096 | 10445 | remote host (100Mbps), tcp, stateless |
| 32*256=8192 | 20894 | remote host (100Mbps), tcp, stateless |
| 64*256=16384 | 41785 | remote host (100Mbps), tcp, stateless |
Determine the bandwidth/throughput in MATLAB
You can replicate this benchmark within MATLAB using the following lines of cod
nchan = 128;
blocksize = 32;
dat = randn(nchan, blocksize); % generate some random data
hdr = [];
hdr.Fs = 1200;
hdr.nChans = nchan;
target = 'buffer://localhost:1972';
duration = 10*hdr.Fs; % total number of samples to write
ft_write_data(target, [], 'header', hdr, 'append', false);
tic; t0 = toc;
for i=1:round(duration/blocksize)
ft_write_data(target, dat, 'header', hdr, 'append', true);
end
t1 = toc;
fprintf('nchan = %d, blocksize = %d: wrote %f samples per second\n', nchan, blocksize, (duration*hdr.nChans)/(t1-t0));
Note that the MATLAB interface to the buffer does not allow you to use a statefull connection or a DMA connection, it only provides the stateless TCP connection.
Determine the time of a single write operation in MATLAB
The following code can be used to determine the time of a single write operation.
nchan = 32;
% target = 'buffer://manzana:1972';
target = 'buffer://localhost:1972';
blocksize = [1:20 30:5:100 200:200:1000];
repeat = 2;
hdr = [];
hdr.Fs = 256;
hdr.nChans = nchan;
ft_write_data(target, [], 'header', hdr, 'append', false);
stopwatch = tic;
for i=1:length(blocksize)
disp(i)
dat = randn(nchan, blocksize(i)); % generate some random data
begtime(i) = toc(stopwatch);
for j=1:repeat
ft_write_data(target, dat, 'header', hdr, 'append', true);
end
endtime(i) = toc(stopwatch);
end
delay = (endtime-begtime)/repeat;
figure
plot(blocksize, delay, '.');