What is the relation between “events” (such as triggers) and “trials”?
FieldTrip can work both with epoched and with continuously recorded data files (both are treated as continuous). However, FieldTrip does assume that in the stream of data, some pieces are of interest. Those are the “trials”. In contrast with other software packages, trials in FieldTrip can have a variable duration. For example, you want to analyze the data in a time window between a stimulus and the subject’s response, and the subject responds faster in one trial than in the next.
To support variable length trials, a generic way of handling those datapieces of interest is needed: the ft_definetrial function. This function returns the segments of the data that you think are interesting. This can consist of variable length trials that start at a stimulus trigger and end at a response trigger, but of course it can also correspond to the trials as they are present in your datafile. The ft_definetrial function translates the events in your datafile into trials. These events are read from the datafile (and the accompanying files) using the ft_read_event function. Events are, for example, stimulus and response triggers, or artifacts, but can also consist of the trials that are potentially already present in the datafile.
The event table contains all events in the data. Ft_definetrial will select pieces of data around those events that interest you, either using a generic definition or using your own “trialfun”. After calling ft_definetrial you can call the ft_preprocessing function, which will read the actual data from disk and apply filtering on the fly.
An example output of the ft_read_event function can be an event that represents a complete trial
>> event(1)
ans =
type: 'trial'
sample: 1
value: []
offset: -300
duration: 900
and/or it can return events that represent a single individual trigger
>> event(2)
ans =
type: 'backpanel trigger'
sample: 301
value: 1
offset: []
duration: []
The duration and offset are represented as empty if they are unknown, in that case you can assume them to be zero.
The ft_definetrial function generates an Nx3 matrix with the segments of the continuous data that should be read in. The first column contains the begin sample (pointer into the datafile), the second column the end sample, and the third column the offset. The offset is the shift that is needed to align the time axis with the event. The default time axis is (0:(Nsamples-1))./Fsample.
After translating the event table into an Nx3 trial definition (cfg.trl), the datapieces are read and filtered by preprocessing. Remembering that trl=[begsample endsample offset], the data from begsample to endsample are read and filtered. Subsequently a time axis is created using the offset (for each trial) that contains the latency in seconds for each sample. The offset field in cfg.trl is not used for reading, but only for attaching the correct latency to each sample.
For a better understanding of the relation between the event offset, trials (or data segments) and the time axis of trials, it helps to look at a number of samples in detail. In the picture below a sampling rate of 1000 Hz is used to allow a simple translation between samples and miliseconds. Remember that FieldTrip works with seconds and not with miliseconds.
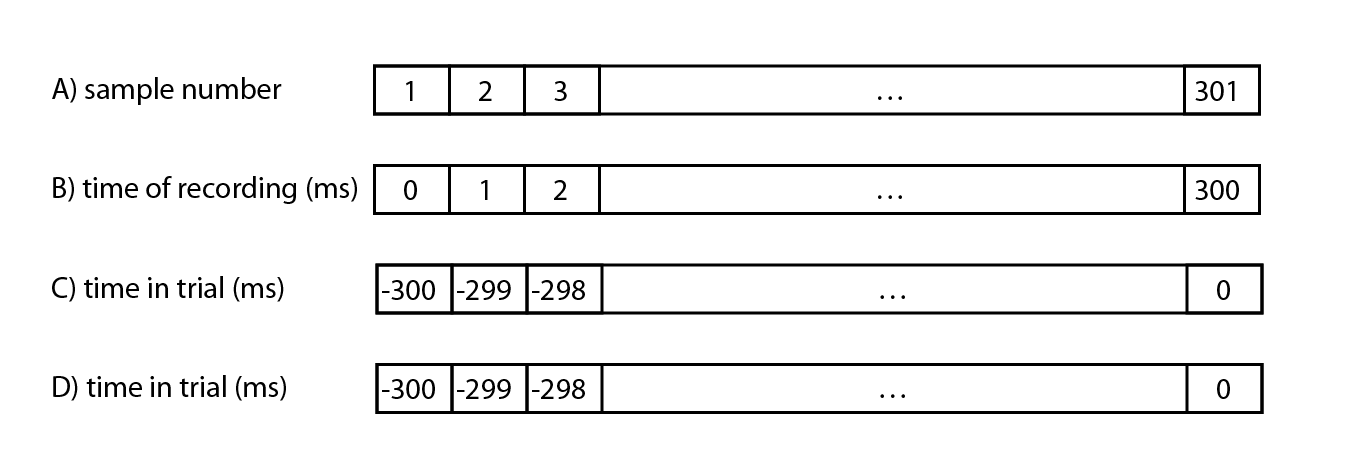
The first row (A) in the figure above shows the samples and the sample numbers. The first sample of the recording (i.e. of the file as stored on disk) is sample 1. Here it is assumed that the sampling rate is 1000 Hz, i.e. one sample per milisecond.
The second row (B) in the figure shows the time of the recording. The first sample is at time t=0 ms.
The third row (C) in the figure shows the time of the first trial based on the “trial” event. The trial event is indicated at sample 1, and has an offset of -300.
The fourth row (D) in the figure shows the time of the first trial based on the “trigger” event. The trigger event is indicated at sample 301, and has an offset of 0.
Both for the “trial” and for the “trigger” event you can define a data segment of interest and attach a local time axis to that data segment. The time-axis for each sample in that data segment is computed as
time = (sample - 1 + offset)/fsample
So for the trial event, the first sample of the trial is at (1-1-300)/1000 = -0.3 s = -300 ms and if you construct a time axis, the first sample in that time axis has a time of -300 ms. The time of that sample is relative to whatever caused that trial.
You can also define trials based on the trigger event. If we don’t define a baseline period, then the 1st sample of the time-axis based on the trigger event is at (1-1-0)/1000 = 0 s = 0 ms. Relative to the trigger, the trigger happens at time zero. If we include a baseline of 300 samples, the first sample in the baseline corresponds to the first sample of the recording. That first sample is then at time t = -300 ms.
In this example (the Subject01.ds dataset used in the tutorials), the events in the data are represented twice. The individual triggers are represented in a trigger channel and in the “backpanel trigger” event, but the triggers also caused the file to be written to disk in epochs. These epochs are represented as the “trial” events.