Automatic artifact rejection
Automatic artifact rejection in FieldTrip is a sophisticated and complicated approach, that without full understanding of all steps involved will unavoidably lead to more harm than good. Only when you fully understand your data and the artifacts you will be dealing with, will you be able to set appropriate parameters for automatic artifact rejection. We therefore advise to first deal with artifacts visually or manually, using either ft_databrowser or ft_rejectvisual. If what follows below is unclear at any point, ask your colleagues or post a question on the mailing list.
Introduction
Prior to the analyses explained in any of the other tutorials, it is best to have artifact free data. Within FieldTrip you do either visual (or manual) and/or automatic artifact detection and rejection.
Background
Artifact rejection aims to reduce variance in the data due to factors unrelated to your experimental conditions. The artifacts in your data can either be physiological or the result of the acquisition electronics. The strongest physiological artifacts in EEG and MEG stem from eye blinks, eye movements and head movements. Muscle artifacts from swallowing and neck contraction can be a problem as well. An example of artifacts related to the electronics are ‘SQUID jumps’ or spikes.
Of course it is best to try to avoid those artifacts in the first place. For instance, you might give your research participants some well-defined time interval between the trials in which they are allowed to blink, but ask them to withhold blinks in the time intervals of interest. Sooner or later, however, you would like to go through the data and make sure artifacts are detected, removed or corrected.
Procedure
The functions ft_artifact_eog, ft_artifact_muscle and ft_artifact_jump are just wrappers around the ft_artifact_zvalue function with some default parameters set. Please look at that function if you want to know in detail how it works.
The following steps are used to detect artifacts in FieldTrip’s automatic artifact rejection (see figure below
- Defining segments of interest using ft_definetrial
- Detecting artifacts using ft_artifact_zvalue, which consists of
- Reading the data (with padding) from disk
- Filtering the data
- Z-transforming the filtered data and averaging it over channels
- Threshold the accumulated z-score
For memory efficiency reasons, during this process we do not read the whole data in memory. An alternative approach is to first read the continuous data in memory, then do artifact rejection, and subsequently segment the remaining data into the trials of interest.
These steps result in an “artifact definition”, a two column array with the onset and offset sample number of every detected artifact. This compares to the trial definition trl, which has an additional column for the offset. The “artifact definition” (the .artfctdef sub-structure) can then, in a separate step, be used to reject (parts of) trials in your trialdefinition (so before reading the data in using ft_preprocessing for your subsequent analysis), or rejecting (parts of) data already in memory. Both methods use ft_rejectartifact. All the steps that the automatic artifact rejection routine takes will now be explained in detail.

Figure: Automatic artifact rejection processes the data in several steps to allow rejection of artifactual time intervals from the trial definition
I. Reading the data (with padding) from disk
Physiological data is often very large. For this reason it is sometimes efficient to read and review only the data you need, instead of reading all the data. This is the reason that in FieldTrip we commonly read the (marker/trigger) events first to determine data segments (trials) of interest, which are then read into memory in a separate step. For how to define trials see Getting started with reading raw EEG or MEG data and the Preprocessing - Segmenting and reading trial-based EEG and MEG data tutorial. However, note that it is also possible and just as valid to do artifact detection on continuous data.
(Automatic) artifact rejected is consistent in this regard: we use our artifact detection and rejection to exclude intervals/trials from our trial definition trl so that in a later step we do not have to read in artifactual data.
What is important to realize is therefore when it comes to reading data, artifact rejection is a two step process: 1) reading data to determine artifacts, 2) read in artifact free data. Furthermore, in the first step we will often read in more data (before and after the trial interval) to be able to deal with filter artifacts (filter-padding) and artifacts that are just outside of our trial but should still be rejected (trial-padding). After artifact rejection this extra data is not used for further processing. Filter- and trial-padding is further explained in a separate section below.
This leads us to the last important issue of reading data in artifact rejection: reading from disk versus reading from memory. In the latter case you will have (raw) datastructure that is already segmented in trials. As in all the cases where we use trial- and filter-padding more data is needed, these cannot be applied and you will become much more sensitive to e.g., filter issues. This will also be an issue when data is not recorded continuously.
II. Filtering the data
After we have read the data of a single trial (plus the extra padding) this data is processed in a way that you think would most exaggerate the particular artifacts you are looking for. In other words, if you know what you are looking for, you can process the data in such a way that it would stand out most. For instance, muscle EMG is mostly expressed in the higher frequencies of the EEG/MEG signal. A bandpassfilter between e.g., 110 and 140 would make use of this knowledge and will result in channels showing a large power amplitude when your subject made a muscle twitch. In a similar way one can optimize filter settings for EOG and SQUID jump artifacts. Examples are given at the end of this page.
Note that this indeed means that you might be doing several runs of artifact rejection to take care of several different kinds of artifacts.
III. Z-transforming the filtered data and averaging it over channels
The automatic artifact detection approach used here is based on three characteristics of artifacts: 1) they occur sparsely in time, i.e. not all the time, 2) they are reflected by larger amplitudes than the brain data (possibly or especially in a particular frequency band), and 3) they occur over multiple channels/electrodes. The filtered data is therefor transformed with the following step
- Per channel/electrode the amplitude of the signal over time is calculated (the Hilbert envelope)
- Per channel/electrode its mean and standard deviation is calculated (over all samples)
- Per channel/electrode every timepoint is z-normalized (mean subtracted and divided by standard deviation)
- Per timepoint these z-values are averaged. Since an artifact might occur on any and often on more than one electrode (think of eyeblinks and muscle artifacts), averaging z-values over channels/electrodes allows evidence for an artifact to accumulate.
This results in one timecourse representing standardized deviations from the mean of all channels.
The formulas for calculating the z-scores are:
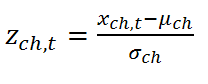
where
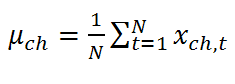

with: N = the total number of time samples.
In the code this formula is formed such as to optimize the calculation of the channel means and standard deviations.
The summation is performed in the following way:
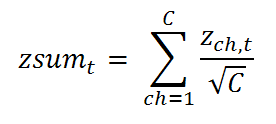
with: C = the number of channels.
IV. Thresholding the accumulated z-score
Now that every timepoint is expressed as a deviation for the mean over time & channels, we can use an artifact detection threshold: all timepoints that are above or below this threshold (cfg.artfctdef.zvalue.cutoff) will be considered belonging to artifacts. Depending on the variance of the artifacts versus the variance of your brain signal a higher or lower threshold has to be set. The lower this threshold the more conservative the artifact detection will behave, the higher the more liberal (see figure). Since these characteristics of the data might vary per experiment and even from one recording to another, care has to be taken to investigate the threshold that works for you.
By using the option cfg.feedback='yes', you enter an interactive mode where you can browse through the data and adjust the cut-off value (i.e., the z-value used for thresholding) according to your data and filter settings.
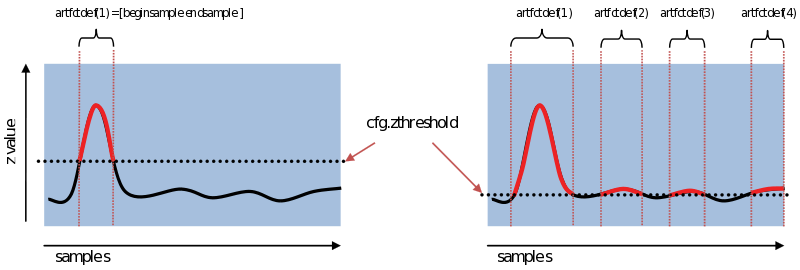
Figure: Setting a higher or lower z-value threshold will make the detection of artifacts more conservative or liberal
Padding
Artifact padding
When a series of continuous time points are detected they are considered part of one artifact period and enter the artifact definition as one start and end sample number. Often the artifact starts a bit earlier and ends a bit later than what the artifact detection is able to capture. Artifact padding (cfg.artfctdef.xxx.artpadding) can then be used to extend the timeperiod of the artifact on both sides. This can also be used to ensure that the artifact will ‘reach into’ the trial that has to be rejected.

Artifact padding extends the segment of data that will be marked as artifact.
Trial padding
You might want to include segments of data preceding or following the trial, e.g., when you want to reject trials with an eye blink right before the trial onset. For this purpose trial padding (cfg.artfctdef.xxx.trlpadding) is used. Trial padding pads data on both sides of the trial with the specified length, such that artifact detection and rejection is also performed for those padded segments.
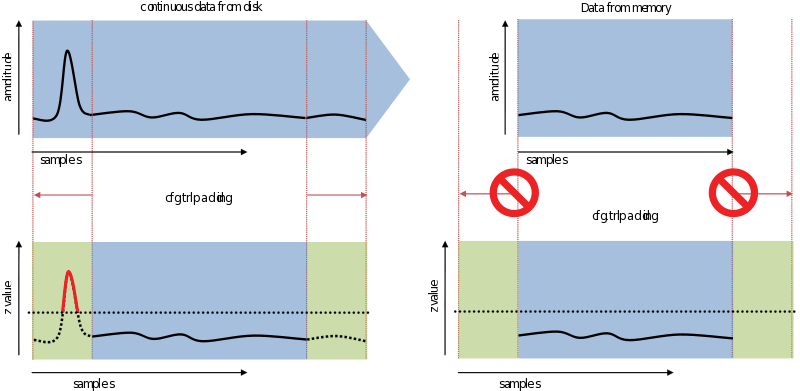
Trialpadding extends the period around the trial where artifact detection is performed
Filter padding
Each artifact type can best be detected with filters of a certain pass band (e.g., pass band of 1–15 Hz for eye blinks, and 110–140 Hz for muscle artifacts). However, filters are known to produce edge effects which can also be detected by the artifact-detection routine and mistaken for real artifacts.
To avoid that, filter padding (cfg.artfctdef.xxx.fltpadding) is used. Always in addition to trial padding (if any) existing trial padding, extra data is read on both sides prior to filtering. After the filtering has been applied, the filter padding is removed again. In other words, the filter padding is used only for filtering, not for artifact detection (see figure).

Figure: Filter padding. Filter padding is only used during filtering and removed afterwards
Combining filter and trial padding
Filter and trial padding are often used together. Trialpadding is first added to the trial, after which filterpadding is added (and removed again after filtering has been applied).
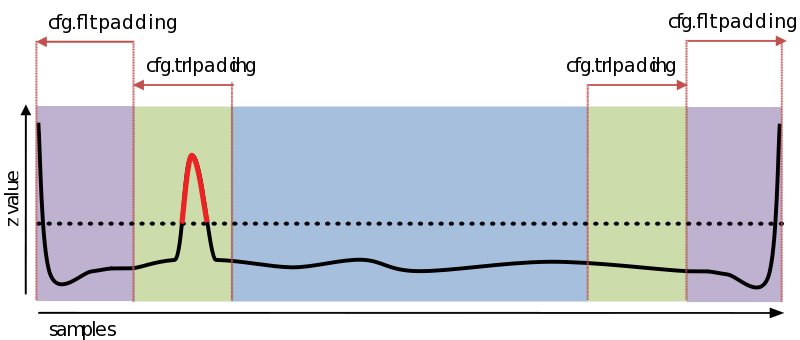
Figure: Filter and trial padding
Negative trialpadding
Negative trialpadding is an option included in automatic artifact rejection because a couple of people have requested its implementation. It’s a bit of a strange one and should only be applied when more appropriate steps are unavailable. This could be the case when trials have, in previous processing steps, been defined larger than necessary for artifact detection, e.g., when one has already included something similar as trial- and filter padding. Filter artifacts might then still be a problem without the possiblity of padding the data (since it is already in memory). Therefore you might want to constrain the artifact detection to a limited part of the trial, i.e., without the edges. You could then specify a negative value for cfg.artfctdef.xxx.trlpadding.
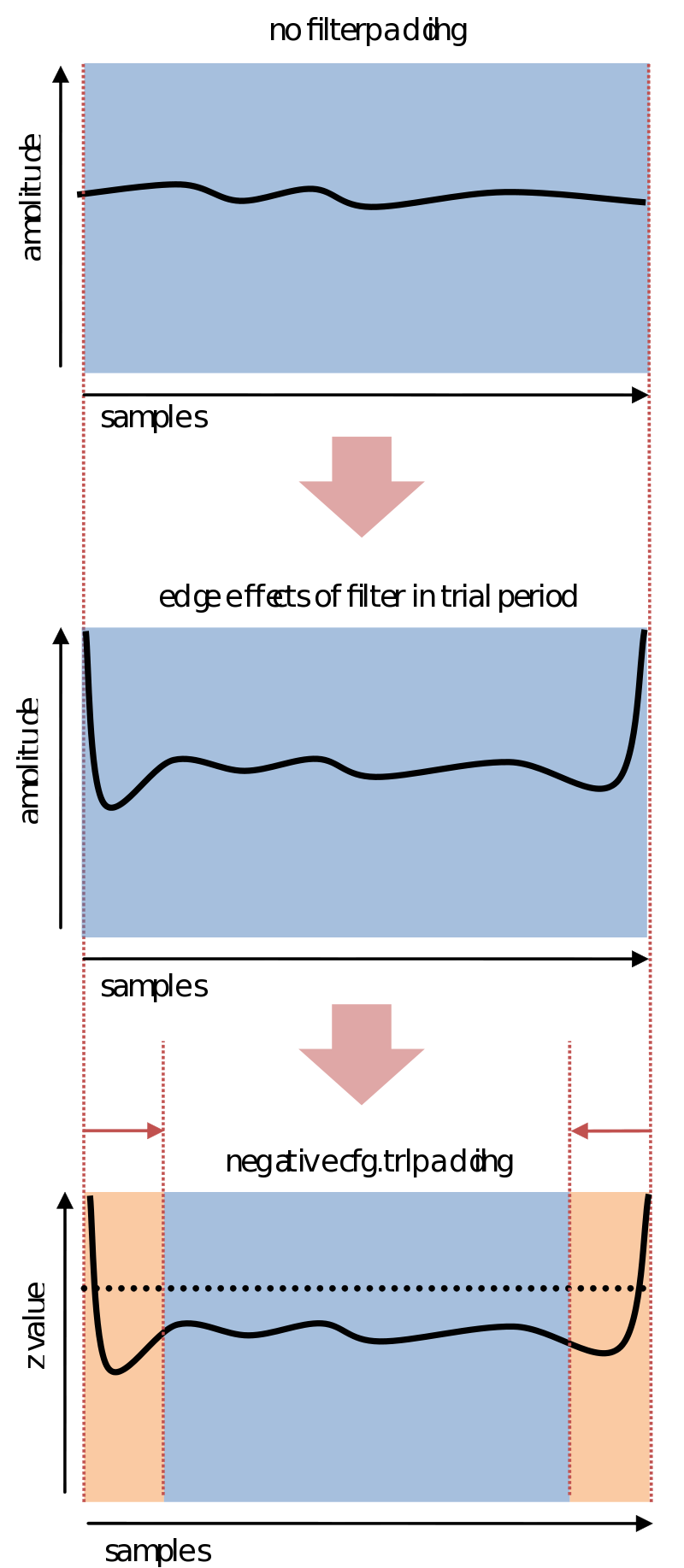
Negative trialpadding excluded the edges of trials for artifact detection
Artifact rejection
After you are satisfied with the detection of artifacts you can either reject the complete trial containing any artifact, or reject only the part with the artifact. The latter option leads to partial trials with variable trial lengths, something that has to be considered especially in anticipation of any trial-based, or average-based statistics.
To remove the detected artifacts from the trial definition (trl) you can add your artifact definition as any field (e.g., .eog, .jump or .zvalue) to the cfg.artfctdef field. For instance:
cfg = [];
cfg.artfctdef.reject = 'complete'; % this rejects complete trials, use 'partial' if you want to do partial artifact rejection
cfg.artfctdef.eog.artifact = artifact_eog;
cfg.artfctdef.jump.artifact = artifact_jump;
cfg.artfctdef.muscle.artifact = artifact_muscle;
data_no_artifacts = ft_rejectartifact(cfg,data);
The output of ft_rejectartifact will contain the cfg.trl, which is the cleaned trial definition, and cfg.trlold which corresponds to the original trials from ft_definetrial).
If you call ft_artifact_zvalue like this cfg = ft_artifact_zvalue(cfg), you can directly feed that output into ft_rejectartifact. Examples of this will be given below.
Examples for getting started
What follows are some case examples of artifacts that you might encounter and some basic settings to start with. You will need to adjust these for your own datasets. The data used in this example is the ArtifactMEG.ds dataset, which was acquired continuously (in contrast with other tutorial data) with trials of 10 seconds.
First we need to define our trial
cfg = [];
cfg.dataset = 'ArtifactMEG.ds';
cfg.headerformat = 'ctf_ds';
cfg.dataformat = 'ctf_ds';
cfg.trialdef.eventtype = 'trial';
cfg = ft_definetrial(cfg);
trl = cfg.trl(1:50,:); % we'll only use the first 50 trials for this example
Jump artifact detection
For detecting jump artifacts, begin with the following parameter
% jump
cfg = [];
cfg.trl = trl;
cfg.datafile = 'ArtifactMEG.ds';
cfg.headerfile = 'ArtifactMEG.ds';
cfg.continuous = 'yes';
% channel selection, cutoff and padding
cfg.artfctdef.zvalue.channel = 'MEG';
cfg.artfctdef.zvalue.cutoff = 20;
cfg.artfctdef.zvalue.trlpadding = 0;
cfg.artfctdef.zvalue.artpadding = 0;
cfg.artfctdef.zvalue.fltpadding = 0;
% algorithmic parameters
cfg.artfctdef.zvalue.cumulative = 'yes';
cfg.artfctdef.zvalue.medianfilter = 'yes';
cfg.artfctdef.zvalue.medianfiltord = 9;
cfg.artfctdef.zvalue.absdiff = 'yes';
% make the process interactive
cfg.artfctdef.zvalue.interactive = 'yes';
[cfg, artifact_jump] = ft_artifact_zvalue(cfg);
Specifying cfg.artfctdef.zvalue.interactive='yes' will open a figure like the one below, which provides you information with respect to the detection procedure and gives you the ability to try out different z-value cutoff values.
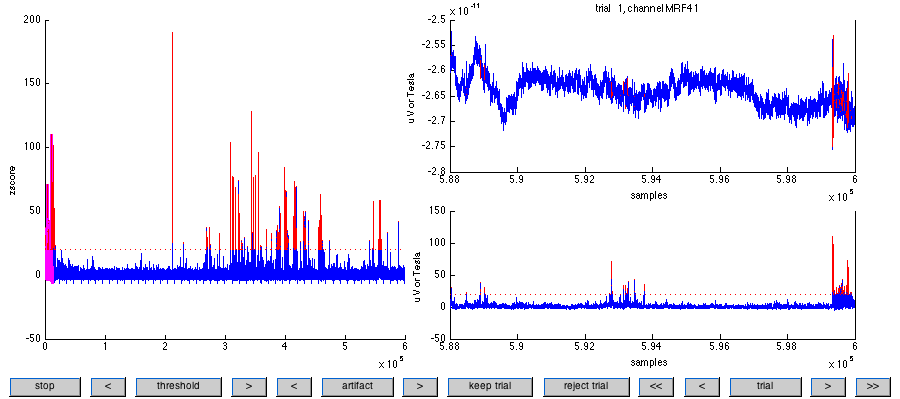
Interactive figure of ft_artifact_zvalue. The left panel shows the z-score of the processed data, along with the threshold. Data points from the current trial are marked in pink and suprathreshold data points are marked in red. The lower right panel shows the z-score of the processed data for a particular trial, and the upper right panel shows the unprocessed data of the channel that contributed most to the (cumulated) z-score. You can browse through the trials using the buttons at the bottom of the figure. Also, you can adjust the threshold, and manually keep/reject trials.
In this example data set, a lot of data points are detected to be a ‘jump’ artifact, although they seem more often ‘muscular’ in nature. A typical jump artifact can be seen below:
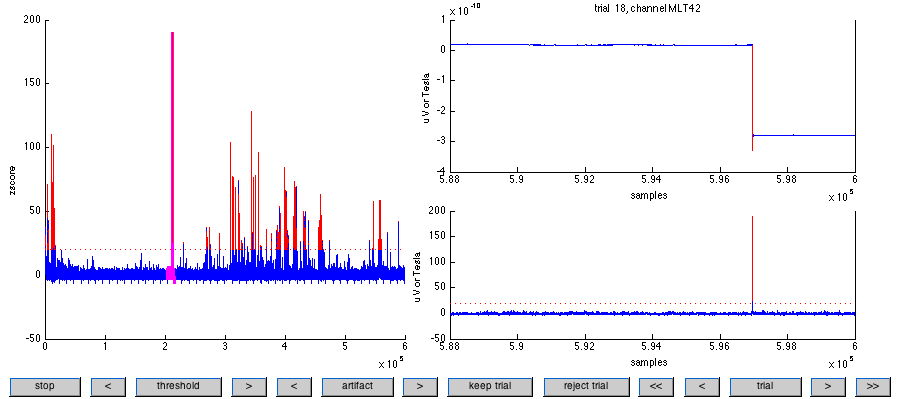
A typical SQUID jump can be observed on channel MLT42, trial 18.
In this example you can easily increase the threshold for the artifact detection to a value of 150. If you subsequently hit the ‘stop’ button you will return to the MATLAB command-line, and the output variable of ft_artifact_zvalue contains the definition of the artifacts in cfg.artfctdef.zvalue.artifact.
Detection of muscle artifacts
The same way as ft_artifact_zvalue is used to detect jump artifacts, it can be used to detect muscle artifacts.
% muscle
cfg = [];
cfg.trl = trl;
cfg.datafile = 'ArtifactMEG.ds';
cfg.headerfile = 'ArtifactMEG.ds';
cfg.continuous = 'yes';
% channel selection, cutoff and padding
cfg.artfctdef.zvalue.channel = 'MRT*';
cfg.artfctdef.zvalue.cutoff = 4;
cfg.artfctdef.zvalue.trlpadding = 0;
cfg.artfctdef.zvalue.fltpadding = 0;
cfg.artfctdef.zvalue.artpadding = 0.1;
% algorithmic parameters
cfg.artfctdef.zvalue.bpfilter = 'yes';
cfg.artfctdef.zvalue.bpfreq = [110 140];
cfg.artfctdef.zvalue.bpfiltord = 9;
cfg.artfctdef.zvalue.bpfilttype = 'but';
cfg.artfctdef.zvalue.hilbert = 'yes';
cfg.artfctdef.zvalue.boxcar = 0.2;
% make the process interactive
cfg.artfctdef.zvalue.interactive = 'yes';
[cfg, artifact_muscle] = ft_artifact_zvalue(cfg);
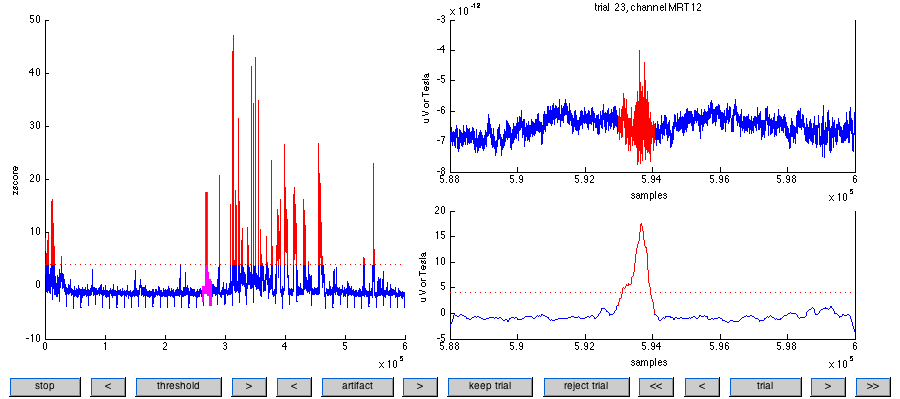
A typical muscle artifact can be observed on channel MRT12, trial 32.
Detection of EOG artifacts
The same way as ft_artifact_zvalue is used to detect jump artifacts,it can be used to detect eye blinks artifacts (EOG). Note that only the EOG is scanned in the eye artifacts case, which will take less time than scanning all MEG channels, which was needed for jump and muscle artifacts.
% EOG
cfg = [];
cfg.trl = trl;
cfg.datafile = 'ArtifactMEG.ds';
cfg.headerfile = 'ArtifactMEG.ds';
cfg.continuous = 'yes';
% channel selection, cutoff and padding
cfg.artfctdef.zvalue.channel = 'EOG';
cfg.artfctdef.zvalue.cutoff = 4;
cfg.artfctdef.zvalue.trlpadding = 0;
cfg.artfctdef.zvalue.artpadding = 0.1;
cfg.artfctdef.zvalue.fltpadding = 0;
% algorithmic parameters
cfg.artfctdef.zvalue.bpfilter = 'yes';
cfg.artfctdef.zvalue.bpfilttype = 'but';
cfg.artfctdef.zvalue.bpfreq = [2 15];
cfg.artfctdef.zvalue.bpfiltord = 4;
cfg.artfctdef.zvalue.hilbert = 'yes';
% feedback
cfg.artfctdef.zvalue.interactive = 'yes';
[cfg, artifact_eog] = ft_artifact_zvalue(cfg);
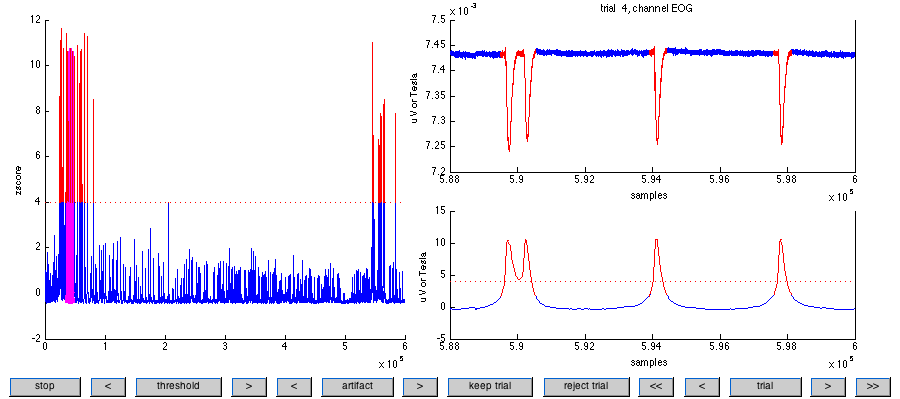
Typical eyeblink artifacts can be observed in trial 4. Note that the trial considers artifacts to precede and last longer than the threshold crossing, by padding data with 0.1 seconds on the left and 0.1 sec on the right
See also this FAQ on the different types of padding.
Suggested further reading
For an introduction to how you can deal with artifacts in FieldTrip in general, you should have a look at the Introduction: dealing with artifacts tutorial. As an alternative to automatic artifact detection, you can manually inspect the trial- and channel-data, see the visual artifact rejection tutorial. Furthermore, you use ICA to remove artifacts from your data, this is explained in the cleaning artifacts using ICA tutorial.
More information on dealing with artifacts can also be found in some example scripts and frequently asked questions. Furthermore, this topic is often discussed on the email discussion list which can be searched like this.
Example scripts
- How to incorporate head movements in MEG analysis
- Independent component analysis (ICA) to remove ECG artifacts
- Independent component analysis (ICA) to remove EOG artifacts
- Combine MEG with Eyelink eyetracker data
- Use denoising source separation (DSS) to remove ECG artifacts
Frequently asked questions
- How can I consistently represent artifacts in my data?
- How can I interpret the different types of padding in FieldTrip?
- How can I use the databrowser?
- How does the filter padding in preprocessing work?
- I am getting strange artifacts in figures that use opacity
- What kind of filters can I apply to my data?
- Why does my TFR look strange (part I, demeaning)?
- Why does my TFR look strange (part II, detrending)?
- Why is there a residual 50Hz line-noise component after applying a DFT filter?