Getting started with Neuralynx data recorded at the Donders Institute
Introduction
In the following, we will describe our procedure to preprocess high-density electrode data recorded by a Neuralynx amplifier and some basic preprocessing steps particularly used in our recording setup.
Background
At the Donders Institute, we record brain activity using an ECoG electrode grid with 252 electrodes. The signal is amplified by a factor of 20 using a headstage amplifier (Headstage 32V-G20, Plexon Inc., Dallas, TX, USA), and subsequently low-pass filtered at 8 kHz and digitized at ~32 kHz sampling frequency using a Neuralynx amplifier (Digital Lynx, 256 channels, Neuralynx Tucson, AZ, USA).
To deal with the tremendous amounts of data recorded each session (approximately 1.5 Gb/min), we develop a recording procedure that allows us to:
- Ensure the correct recording and storage of a particular session (using the .nrd Neuralynx dataformat).
- Use a format that allows us to keep long-term storages copies of the original datasets (using the ft_spikesplitting function to split the original file and store it in the .sdma file format).
- Obtain a 1 kHz downsampled working copy of the LFP data that can be conveniently used by the ft_preprocessing and other FieldTrip functions.
- Obtain a 1 kHz downsampled estimate of the multi-unit activity (MUA).
- Eventually obtain an estimate of single-unit activity (SUA), depending on the electrode grid configuration.
The downsampling of the original 32 kHz data into the LFP and MUA data is done using the ft_spikedownsample function.
Here, we will briefly explain how we use FieldTrip to obtain these representations of the data. In addition, we will describe some basic preprocessing steps (i.e., relabeling channels and using a montage configuration to re-reference the data). To known more about the characteristics of the fileformats used in our recording and analysis setup, please check the page on spike and LFP dataformats for a description of Neuralynx and Plexon data formats supported by FieldTrip. For general information about getting started with Plexon and Neuralynx using FieldTrip, please refer to the getting started with Neuralynx and getting started with Plexon sections.
Data format conversions
The overall flow of datafile formats transformations that we currently use in our recording setup, looks as follow
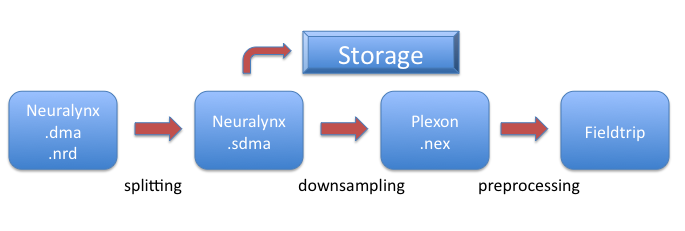
Data splitting
The Neuralynx acquisition system provides the data in a format containing the raw data directly after A/D conversion. During each recorded session, the .nrd file is written directly to an external Lacie RAID-0 hard disk that is connected by firewire 800. The .nrd datafiles contain a 16kB ASCII header, followed by the multiplexed 32-bit channel-level data (see also this page). The huge size of these multiplexed files (>100 Gb per 45 minute session) precludes them for efficient post-processing. Using the FieldTrip ft_spikesplitting function, we split the .nrd file into separate files for each channel, containing exactly the same 32-bit information. These files are written into a single directory which usually has the extension .sdma, since it contains the “split dma” channels. We refer to this directory as the output dataset, whereas the .nrd file is the input dataset.
An example of the configuration for spikesplitting is provided belo
cfg = [];
cfg.dataset = 'recording.nrd';
cfg.output = 'recording.sdma'; % output directory
cfg.latency = [0 inf]; % define the segment of the original data to split
cfg.format = 'int32';
cfg.channel = 'all';
cfg = ft_spikesplitting(cfg);
It is also important to note that:
-
The information extracted from a single .nrd file also contains the timestamps, trigger and event information (see below for details).
-
The new version of Neuralynx software also reserves an initial segment of the recorded file to write a header. The FieldTrip function ft_spikesplitting could extract this information and write it in a .txt file in the dataset directory. According to Neuralynx, this header will be operative in future releases.
-
The .sdma dataset format is used as our back up copy and long-term storage. After creating two backup copies, the original .nrd file is erased.
-
For the same reason, the data is kept as close as possible to the original recorded file. We do not apply further preprocessing during this step.
Data downsampling
The ft_spikedownsample function preprocesses and downsamples the LFP data sampled at 32 KHz to 1 kHz. The LFP data at 1 kHz can subsequently be analyzed.
An example of the configuration for ft_spikedownsample is provided belo
cfg = [];
cfg.dataset = inputDirectory; % i.e. the *.sdma directory
cfg.output = outputDirectory; % use the suffix _ds
cfg.channel = 'all';
cfg.latency = [0 inf];
cfg.dataformat = 'plexon_nex';
cfg.calibration = 1/(64*20);
cfg.fsample = 1000;
cfg.method = 'resample';
cfg.timestampdefinition = 'sample';
% ... to be continued below
This basic configuration structure is necessary to downsample the data. Optionally, we can add other preprocessing options that allow us to obtain the LFP. E.g., to implement a 250 Hz low-pass filter for the LFP signal
cfg.preproc.lpfilter = 'yes';
cfg.preproc.lpfreq = 250;
cfg.preproc.lpfiltord = 2;
cfg.preproc.lpfilttype = 'but';
cfg.preproc.lpfiltdir = 'twopass';
cfg.preproc.precision = 'double';
cfg = ft_spikedownsample(cfg);
By using the option format in the configuration structure, we can choose the file format to which the downsampled LFP data will be written. FieldTrip can write the file dataset in several formats (see ft_write_data). We use the Plexon .nex format which provides us the best compromise between data read/write speed and storage capacity. To get more details about the Plexon dataformats, please see the getting started with Plexon data section. The output dataset directory for the LFP data uses the suffix _ds.
The raw .nrd file and the split DMA files contains AD values that are not scaled in uV and require an additional factor of 64x. In addition, our acquisition system includes a Plexon headstage with an additional amplification of 20x. Thus, in our case the calibration should be specified as 1/(64*20).
Dealing with timestamps
The different file formats can have different timestamp definitions. The Neuralynx acquisition system has a timestamp clock that ticks at approximately 1MHz, which, when sampling at 32kHz means, that subsequent samples are ~31 clockticks apart from each other. In a channel that was sampled at 1kHz subsequent samples are ~1009 clockticks apart
In contrast, the timestamp clock in the Plexon acquisition hardware ticks at the native sampling frequency of 40kHz, meaning that subsequent samples in a Plexon file are 40000/Fsample timestamps apart. In a channel that is sampled at 40kHz subsequent samples are one clocktick apart, in a channel that is sampled at 1kHz the subsequent samples are 40 clockticks apart.
In FieldTrip the relation between the timestamps and the samples is represented in the header. If you call ft_read_header on your datafile, you’ll see something like this
>> hdr = ft_read_header('256_noev_DigitaLynx_DMA.nrd')
hdr =
Fs: 32556
nChans: 274
nSamples: 461502
nSamplesPre: 0
nTrials: 1
label: {274x1 cell}
FirstTimeStamp: 1007379572
TimeStampPerSample: 30.7200
orig: [1x1 struct]
or this
>> hdr = ft_read_header('p021parall.nex')
hdr =
nChans: 15
Fs: 1000
nSamples: 9463587
nTrials: 1
nSamplesPre: 0
label: {15x1 cell}
FirstTimeStamp: 0
TimeStampPerSample: 40
orig: [1x1 struct]
The hdr.TimeStampPerSample represents the increment of the clockticks per sample of the LFP recording. Another thing to notice is that the timestamp clock starts ticking at the start of the acquisition (when you switch the system on), not on the start of the recording (when you start writing to disk). This means that there is a positive offset in the timestamps (see hdr.FirstTimeStamp).
Samples and timestamps are related to each other according to
TimeStamp = FirstTimeStamp + TimeStampPerSample*(SampleNumber - 1);
SampleNumber = (TimeStamp - FirstTimeStamp) / TimeStampPerSample + 1;
Note that timestamps start counting at zero, whereas in MATLAB/FieldTrip convention the first sample of the recording is sample 1.
Dealing with triggers
During acquisition the 16 bit trigger channel is sampled with 32kHz, just like all other channels. Consequently in the .ndr DMA log file there is a “ttl” channel that represents the triggers. The ttl channel is a 32-bit channel, although only 16 of those bits are connected to the trigger input.
After spikesplitting, there is a .ttl file containing the same 32kHz representation of the trigger channel as in the DMA log file. There are also two files (.tsl and .tsh) that represent the lowest and highest 32-bits of the 64-bit timestamp channel. The Neuralynx timestamp channel has a clock rate of 1MHz, i.e. 1e6 timestamps per second, or approximately 32 timestamps per data sample at 32kHz (1e6/32556).
After spikedownsampling, the continuous sampled LFP channels are not represented at 32kHz any more, but typically at 1000 Hz. That means that the samples at which the triggers occur in the .ttl channel cannot directly be mapped onto the samples in the LFP channels. The method to link the original triggers to the downsampled data is by means of the timestamps. The ft_spikedownsample function has the option cfg.timestampdefinition which can be ‘orig’ or ‘sample’. If you specify it as cfg.timestampdefinition=’sample’, the timestamps in the downsampled LFP channels will correspond to the original samples, i.e. there will be 32566 timestamps per second in the downsampled data. The first downsampled sample will be at timestamp 17, because the first 32 original samples are all compressed into the first downsampled sample. If you specify cfg.timestampdefinition=’orig’, the downsampled LFP data will be written to disk with the original timestamp definition with 1e6 timestamps per second.
Data preprocessing
Data sessions that had been subsequently split, downsampled and stored in Plexon .nex format are suitable to be preprocessed for further analysis. To get a general idea of how to proceed, we recommend to read the documentation of the FieldTrip ft_preprocessing function and the preprocessing tutorials in the tutorial documentation . Here, we will focused on how to read the Plexon dataset directories (_ds) which contain multiple .nex files. A basic configuration structure is provided belo
cfg = [];
cfg.dataset = dataset; % "_ds" dataset directory
cfg.dataformat = 'plexon_ds'; % this is optional, and will be auto-detected
cfg.headerformat = 'plexon_ds'; % this is optional, and will be auto-detected
data = ft_preprocessing(cfg)
The specification of the dataformat and headerformat options as combined_ds ensures that the appropriate low-level FieldTrip reading function will be called to read the multiple single-channel Plexon .nex files contained in the dataset directory. After preprocessing, we can obtain a data structure like this:
data =
hdr: [1x1 struct]
label: {254x1 cell}
trial: {[254x3001 double] [254x3001 double] [254x3001 double]}
time: {[1x3001 double] [1x3001 double] [1x3001 double]}
fsample: 1000
cfg: [1x1 struct]
Dealing with changing of channel labels
Neuralynx uses the expression csc (from continuous sampled channel) in addition with a number (e.g., 010) to label the channels. This labels are different from the names assigned to the electrodes in the electrode array. To keep consistency on the labels (this is especially important for plotting the channels), we apply a montage structure that consist of a matrix of correspondences that changes the original labels by the new ones. By using the FieldTrip function ft_preprocessing, with the montage as a part of the cfg option montage, channel labels can be modified.
All montage files for our particular experiment are available upon request. An example of changing the channel labels is provided belo
load kurt_montage_rename_plx2elec.mat
cfg = [];
cfg.montage = montage;
data = ft_preprocessing(cfg,data);
It is important to note that to change labels in our recordings on Kurt, we use two montages structures. This is because recordings between sessions 17 and 60 headstages were inversely connected to the electrode connectors. In this case, the correct montage file to use is kurt_montage_rename_plx2elec_17_60.mat. After session number 60, headstages were correctly positioned. For later sessions therefore the montage file kurt_montage_rename_plx2elec.mat should be used. These files are available upon request.
Dealing with data re-referencing
Similar to what we described in the last section, re-reference of the signal to a particular electrode or electrode group could be performed using a montage structure and the FieldTrip ft_preprocessing function. We implemented 2 montage structures to be used together with our datasets recording. These files are also available upon request.
Plotting Options
To visualize the data, we take advantage of the several specialized plotting functions available in FieldTrip. To obtain a detailed description of the functions and their implementation, please refer to Plotting data in the tutorial documentation section.
Dealing with layouts
Datasets obtained from electrocortigraphic (ECoG) grids might be particular for each recording. Number, position and relation with anatomical number of the electrodes used in a grid might differ completely to the same parameters in another ECoG grid. The FieldTrip function ft_prepare_layout allows the possibility to create a particular layout structures of a electrode grid from an image of the grid. In the following, we will show the layout structures that are currently used in our datasets. These layouts are available upon request.
For example, a schematic layout of the 256 electrode grid might be obtained using the following the function ft_layoutplot:
load kurt_layout_schematic_common
cfg = [];
cfg.layout = ft_layout;
ft_layoutplot(cfg)
To obtain something like this:

An example of the same layout, containing time-frequency charts at the site of each electrode (obtaining with the FieldTrip function ft_topoplotTFR) is provided below:

–x367)